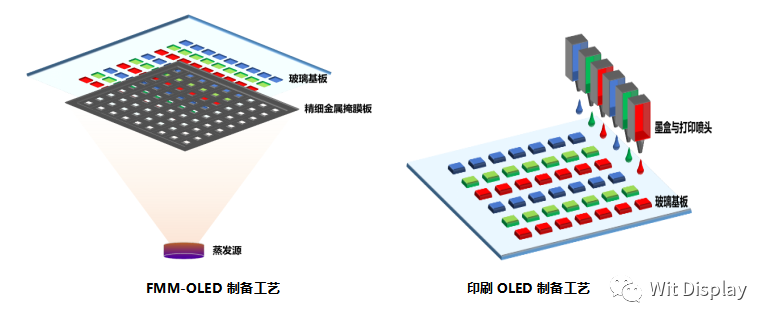
動態(tài)隨機存取記憶體(DRAM)設(shè)計正走向立體(3D)堆疊架構(gòu)。電子產(chǎn)品對尺寸及效能要求日益嚴(yán)苛,促使DRAM制造商積極采納3D堆疊與Wide I/O設(shè)計架構(gòu),以在
動態(tài)隨機存取記憶體(DRAM)產(chǎn)業(yè)已形成三巨頭的態(tài)勢。2013年7月31日,美國的美光(
邁進(jìn)0")
圖1 三大DRAM公司市占率分析 資料來源:DRAMeXchange
三巨頭壟斷DRAM市場 臺DRAM業(yè)者拚轉(zhuǎn)型
過去PC當(dāng)?shù)罆r,大部分產(chǎn)能聚集于標(biāo)準(zhǔn)型DRAM。一旦PC市場蓬勃,易造成DRAM短缺,單價開始升高;此時,廠商也會開始增加產(chǎn)能,使得供給追上需求,但也容易導(dǎo)致供給失衡,使價格崩跌。隨著PC市場衰退,標(biāo)準(zhǔn)型DRAM景況愈來愈嚴(yán)峻,但是由于三大公司的寡占,供給得以控制,并維持價格的穩(wěn)定與上揚。以結(jié)果而言,確實讓存活的業(yè)者受惠,卻是留給臺灣剩下不到10%的市場。臺灣的DRAM廠商紛紛退出標(biāo)準(zhǔn)型DRAM。在歷經(jīng)茂德轉(zhuǎn)型為無晶圓廠(Fabless)、華邦轉(zhuǎn)型為輕晶圓廠(
臺灣的DRAM廠商雖然在利基型DRAM市場耕耘許久,但是大多著力于特殊型DRAM,出貨又以低容量產(chǎn)品為主。低容量記憶體的核心陣列(Core Array)在面積上所占據(jù)的比重較低,周邊電路得以沿襲舊有的設(shè)計或進(jìn)行微幅的修改。長久以來,臺灣的DRAM廠商依循摩爾定律(Moore's Law),透過導(dǎo)入更先進(jìn)的制程技術(shù),增加每片晶圓上的晶片數(shù),降低單位的生產(chǎn)成本。只不過,先進(jìn)制程的取得幾乎都是經(jīng)由外部技術(shù)移轉(zhuǎn)。臺灣的DRAM廠商在低功率的制程發(fā)展與高能效的規(guī)格設(shè)計等附加價值,與三大公司相比仍有一段落差。
臺灣的DRAM產(chǎn)業(yè)轉(zhuǎn)型造就了獨特的DRAM無晶圓廠與晶圓代工的經(jīng)營模式。因為無論制造、封裝、測試皆委由第三方,無晶圓廠的資本密集程度較低。又因為臺灣的半導(dǎo)體產(chǎn)業(yè)上、下游銜接完整,因此具有發(fā)展優(yōu)勢。不過,即便是利基型產(chǎn)品,售價仍舊隨著時間的推移而下跌。為了維持收入,無晶圓廠必須提高現(xiàn)有產(chǎn)品的銷量、取得相稱的成本降幅,或?qū)肜麧欇^高的新產(chǎn)品,在總量上抵消或彌補預(yù)期的售價跌幅。若要提高產(chǎn)品的銷量,第三方必須分配更大的產(chǎn)能或提高良率。DRAM晶圓代工廠因為無法自外于產(chǎn)業(yè)整并的影響,同時自身的財務(wù)狀況也非十分健全,通常難以保證長期的產(chǎn)能;因此,投入改變傳統(tǒng)架構(gòu)的客制化DRAM的新產(chǎn)品開發(fā)似乎較為可行。
與終端產(chǎn)品應(yīng)用緊密結(jié)合 客制化DRAM勢力抬頭
利基型與標(biāo)準(zhǔn)型的差異是其客制化的程度較高,因而與終端產(chǎn)品的結(jié)合也更緊密。譬如,行動型DRAM是按季議價接單制造,使得供給符合需求,生產(chǎn)行動型DRAM的廠商就能夠產(chǎn)生利潤。受惠于智慧型手機應(yīng)用的拓展,單機搭載的行動型DRAM位元量也隨之攀升,但是三大公司在行動型DRAM的市場占有率接近100%,臺灣的DRAM廠商的影響力幾乎無足輕重。
無論是標(biāo)準(zhǔn)型或行動型DRAM,很自然地成為寡占市場上少數(shù)決定的游戲。最明顯的例子是,三大公司可以在標(biāo)準(zhǔn)正式公布之前,就開始試產(chǎn)與送樣,而且總能為他們所認(rèn)可的標(biāo)準(zhǔn)找到客戶,并提前在其產(chǎn)品上的使用做設(shè)計。即便如此,三大公司也認(rèn)知DRAM產(chǎn)業(yè)正逐漸走向客制化。換言之,DRAM廠商現(xiàn)在要與客戶共同開發(fā),提供記憶體的解決方案。客制化的程度可以小到修改標(biāo)準(zhǔn)型DRAM某一個對特定應(yīng)用相對重要的時序參數(shù),大到使用矽穿孔(Through Silicon Via, TSV)的異質(zhì)晶片堆疊架構(gòu),打造新的利基型DRAM。
超越摩爾定律 廠商競逐3D DRAM技術(shù)
半導(dǎo)體產(chǎn)業(yè)在預(yù)期成長趨緩、產(chǎn)能擴充受限、制程微縮接近極限等考量之下,超越摩爾定律,讓元件朝垂直方向整合,就變成追求的目標(biāo)。
所謂的「三維(3D)整合」在形成多層的主動元件時產(chǎn)生許多不同的方法,這里或許可以簡單地以制作順序區(qū)分為循序式(Sequential)與并行式(Parallel)兩種。前者意指上、下層主動元件的形成是在同一晶片上循序漸進(jìn),層層累積;后者則意指上、下層主動元件的形成是各屬不同晶片分別并行,片片堆疊。它們的差異可以用上、下層主動元件的垂直距離加以區(qū)別--循序式三維整合的垂直距離小于1微米(μm),并行式三維整合的垂直距離通常大于10微米。
循序式三維整合是單晶同質(zhì)整合,因此追求裝填密度的提升若非唯一也會是它最大的訴求。并行式三維整合允許不同的制程與技術(shù)節(jié)點的晶片堆疊,可以將各自的優(yōu)點結(jié)合,也就是異質(zhì)整合。異質(zhì)整合依技術(shù)與設(shè)備到位的情況來看,由前段制程提供者(如晶圓代工廠)向后延伸,因為可以主動地開發(fā)載具,比較容易獲得進(jìn)展。由后段制程提供者(如封裝測試廠)向前延伸,因為普遍缺乏設(shè)計能力,只能被動地取得載具,因此需要較長時間發(fā)展。
DRAM核心的記憶單元將儲存
[@B].利基型3D DRAM典范—HMC[@C] .利基型3D DRAM典范—HMC
HMC是DRAM與邏輯晶片的異質(zhì)整合,以矽穿孔垂直連線,以微凸塊(Micro Bump)接合,堆疊四或八顆做為資料儲存的DRAM晶片在一顆做為管理與介面的邏輯晶片之上。它的進(jìn)展是由美光主導(dǎo),如圖2所示:首先藉著第一代原型產(chǎn)品的概念驗證,并且在2011年9月英特爾科技論壇(Intel Developer Forum)展示,引起廣泛的注意;之后成立聯(lián)盟共同發(fā)展,公布第二代量產(chǎn)產(chǎn)品的規(guī)格書,開始試產(chǎn)與送樣;然后再有聯(lián)盟成員的廠商配合以現(xiàn)有產(chǎn)品做系統(tǒng)呈現(xiàn)或未來產(chǎn)品做規(guī)畫。
邁進(jìn)1")
圖2 DRAM晶片堆疊過去3年的發(fā)展
.標(biāo)準(zhǔn)型DRAM堆疊遇瓶頸
標(biāo)準(zhǔn)型DRAM晶片堆疊,特別是第三代雙倍資料率記憶體(DDR3),從2010年開始就有廠商陸續(xù)宣示已經(jīng)準(zhǔn)備就緒,但是進(jìn)展卻遠(yuǎn)不如利基型DRAM順?biāo)臁F渲幸粋€原因,可能是因為對效能的提升通常與下世代產(chǎn)品預(yù)期相符,例如DDR3到DDR4。在成本、技術(shù)、產(chǎn)業(yè)鏈等考量下,客戶寧可等待下世代產(chǎn)品,也不愿冒險使用。因此有些人認(rèn)為標(biāo)準(zhǔn)型DRAM晶片堆疊也許要在現(xiàn)在DDR世代結(jié)束之后才會開始。
行動型DRAM使用的一種寬輸出/入(Wide I/O)架構(gòu),系將四條獨立的128位元200Mbit/s通道置于單一晶片上,并可以透過并行式三維整合堆疊至多四顆晶片,提高記憶容量。固態(tài)技術(shù)協(xié)會(JEDEC)在2011年9月28日頒布MO-305產(chǎn)品輪廓,2012年1月5日頒布JESD229規(guī)格書,確實將此一架構(gòu)與介面標(biāo)準(zhǔn)化,但在少數(shù)實際產(chǎn)品應(yīng)用卻出現(xiàn)無法與JEDEC標(biāo)準(zhǔn)相容的介面,如圖3所示。因為在系統(tǒng)上異質(zhì)整合須要求DRAM晶片與邏輯晶片更密切的結(jié)合,前段的設(shè)計、制造與后段的封裝與測試技術(shù)變得環(huán)環(huán)相扣,這些需求其實都與客制化無異,標(biāo)準(zhǔn)化扮演的角色似乎也隨著DRAM產(chǎn)業(yè)整并而越來越弱。
邁進(jìn)2")
圖3 三星 Wide I/O DRAM與JEDEC規(guī)范的微凸塊分配的差異
DRAM的發(fā)展趨勢--大頻寬、高能效
DRAM的發(fā)展可以從過去其資料傳輸?shù)募夥孱l寬,與傳輸每位元所需要的能源效率的改變觀察(圖4)。隨著產(chǎn)品世代的更迭,DRAM為了符合效能需求提供更大的尖峰頻寬,同時也提高能源效率以維持功率中立(Power Neutrality)。行動型DRAM的功率大約1瓦(W),繪圖型DRAM的功率大約4瓦,高效能計算(High-performance Computing, HPC)用DRAM的功率則是15瓦或更大。可以預(yù)期這個趨勢將繼續(xù),JEDEC商定中的Wide I/O 2與高頻寬記憶體(High Bandwidth Memory, HBM)基本上都在這個能源效率擠壓在小于5pJ/b的設(shè)計空間探索,使得傳統(tǒng)的DRAM架構(gòu)逐漸難以應(yīng)付。
邁進(jìn)3")
圖4 DRAM頻寬增加與能效提升趨勢分析
只在意核心通量(Core Throughput)的設(shè)計,會將輸出/入位元數(shù)與資料傳送率當(dāng)做折衷的參數(shù),輸出/入埠越寬或資料傳送率越高,都將增加功率消耗與晶片面積。為了維持功率中立,就要減少輸出/入電容、擺幅與資料轉(zhuǎn)變,異質(zhì)整合的晶片堆疊就有這些益處。
另一方面,過去20年間DRAM核心陣列的傳播時延,受限于列線的RC時間常數(shù),平均每年只減少不到5%。圖5顯示W(wǎng)ide I/O DRAM的列周期時間(Row Cycle Time, tRC),相較于各個DDR世代,并未出現(xiàn)太大的改變。隨機列周期時間決定存取DRAM的潛伏(Latency),是記憶體階層設(shè)計的重要參數(shù)。
邁進(jìn)4")
圖5 Wide I/O DRAM與不同DDR世代的列周期時間比較
處理器晶片內(nèi)嵌的最后一層快取記憶體(Last Level Cache, LLC),通常在記憶體階層的第二或第三層,與外置的做為主記憶體的DRAM,不論是延遲或容量,在比值上都有明顯的差異(圖6)。換言之,大部分的資料被存放在速度很慢的主記憶體,這就是記憶墻(Memory Wall)的表征。近來處理器的核心數(shù)迅速增加,它們之間存在的鴻溝也越來越大。
邁進(jìn)5")
圖6 存在目前記憶體階層的延遲時間與儲存容量鴻溝
以英特爾(Intel)的處理器為例,在短短的3年內(nèi),其最大核心數(shù)從8上升至15,因此再插入一層以分立DRAM晶片做成的快取記憶體似乎可行。這個新的快取DRAM的延遲約在10~25奈秒(
(本文作者為工研院資通所技術(shù)組長)

關(guān)注我們

公眾號:china_tp
微信名稱:亞威資訊
顯示行業(yè)頂級新媒體
掃一掃即可關(guān)注我們
產(chǎn)品供求| 雜志期刊| 協(xié)會服務(wù)| 專題集| 關(guān)于我們|網(wǎng)站地圖|版權(quán)聲明| 廣告服務(wù)
Copyright © 2018 深圳市美嘉投資有限公司. All Rights Reserved 版權(quán)所有 粵ICP備12048185號-1
中華顯示網(wǎng)所載文章、數(shù)據(jù)僅供參考,使用前務(wù)請仔細(xì)閱讀法律聲明,風(fēng)險自負(fù)。


媒體合作:0755-86149081 廣告咨詢:0755-86149131 Email:314106127@qq.com